Forecasting the evolution of dynamic environments is crucial for autonomous agents. While generative world models have recently achieved high photorealism in 2D video synthesis by mixing ego-motion and environmental dynamics within the image plane, they exhibit physical inconsistencies, such as morphing or vanishing objects, especially over long time horizons. In this paper, we propose FR3D, a world model that predicts a persistent 3D latent representation for future dynamic 3D reconstruction. Unlike prior works that treat the world as a sequence of image-based features, FR3D explicitly decouples the 3D evolution of the scene from the agent's trajectory, treating the inferred ego-motion as a latent proxy for action. This disentanglement resolves the ambiguities between self-motion and world-motion, ensuring geometric consistency into the future. Furthermore, we introduce a teacher-student distillation strategy that leverages the spatial "common sense" of off-the-shelf foundation models, leading to robust zero-shot generalization. Extensive experiments demonstrate FR3D's strong performance for future dynamic 3D reconstruction from monocular observations across multiple datasets, even 2 seconds into the future.
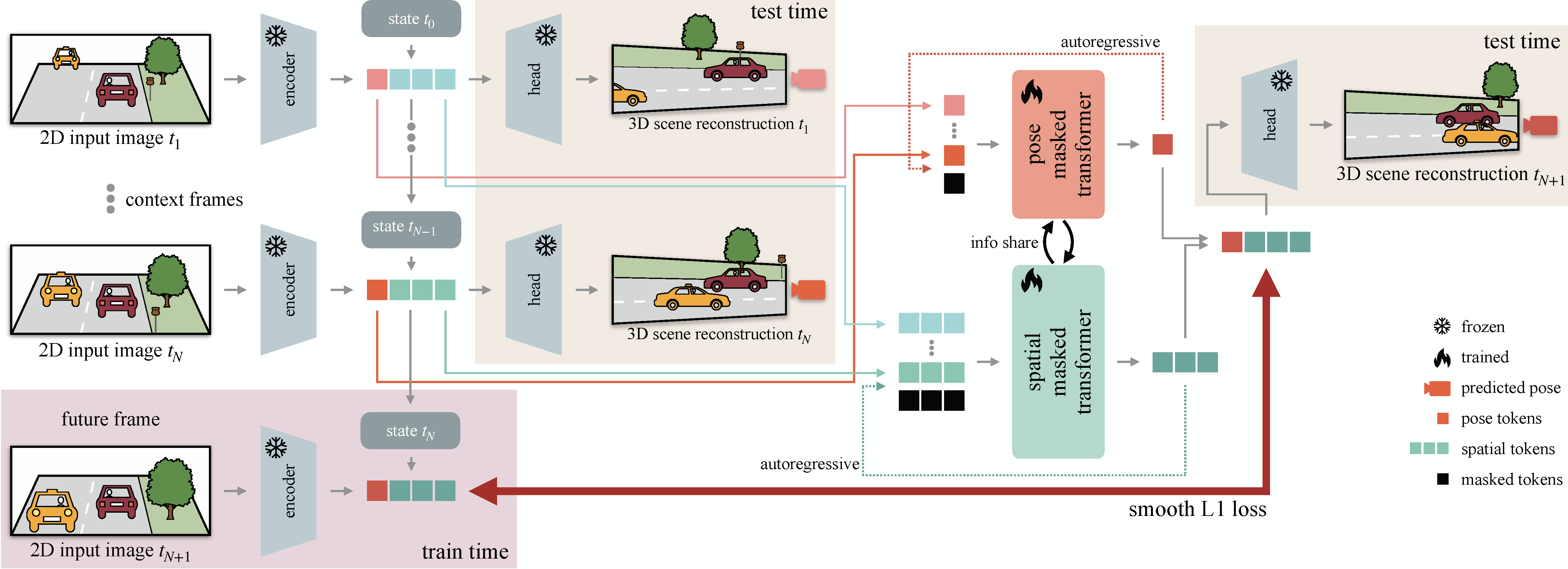
Our approach targets predicting how a 3D scene evolves over time and forecasting the most likely camera motion. Displayed above, we propose a world modeling approach for dynamic 3D reconstruction. Our key idea is to learn how to temporally operate in the latent space of a pre-trained, feed-forward 3D reconstruction model, thereby effectively disentangling camera motion from the reconstructed 3D scene structure and potentially induced motion. For that, we propose an autoregressive teacher-student distillation training strategy that yields the first 3D world model for dynamic 3D reconstruction learning to propagate scene states and agent poses within a unified 3D latent space.
After training our pose and spatial forecasting models, FR3D can temporally operate on the latent space of the frozen, feed-forward 3D reconstruction model (i.e. CUT3R). In contrast to prior works that rely on dataset-specific decoders (e.g., DINO-Foresight, VFMF), our frameworks' main advantage is that we can leverage CUT3R's full pipeline, i.e., encoder, decoders, and heads, which are pre-trained for approximately a month on 32 datasets, thereby inheriting its strong generalization capability.
Our unified framework tackles future dynamic 3D reconstruction on several outdoor datasets (Waymo, KITTI, nuScenes). Select each tab below to explore the results for each dataset. Since our forecasting model does not predict RGB, we augment the point clouds (context and future) with the RGB frames.
Our method can forecast how dynamic 3D scenes evolve in a feed-forward manner.
Our method exhibits strong zero-shot generalization on KITTI.
Our method exhibits strong zero-shot generalization on nuScenes.
In the qualitative results, we show the context frames as RGB and the 3D reconstruction produced by our model and the oracle. We indicate the ego-camera poses estimated by the oracle in green, both for the context and the future frames. Instead, the forecasted ego trajectory is indicated in blue. As an upper bound, we show the 3D reconstruction performance of the oracle, given the future input images.

The figure above shows qualitative zero-shot results of FR3D on nuScenes and KITTI, with two different challenging dynamic scenes for each dataset. Significant domain shifts occur between Waymo (where the FR3D forecasting model is trained) and the two datasets here. For example, the aspect ratio of the KITTI inputs is significantly wider than that of Waymo (see Figure at the top of the project page). Yet, all scenes show remarkable forecasting performance by FR3D, closely matching its oracle model.

In the figure above, we show another interesting qualitative result with a zero-shot prediction of our model on the nuScenes. The scene exhibits a left-hand turn. In the context, it can be seen that the turn has just started (visible in the camera poses). Our model correctly predicts a smooth completion of the turn throughout the rollout (blue cameras). Remarkably, the pose prediction of the oracle (right) is more jittery than that of our model, although our model is trained to mimic the oracle predictions. However, we can explain the improvement as our model learns on noisy tokens thanks to our autoregressive strategy. This makes it robust against the oracle tokens, too.
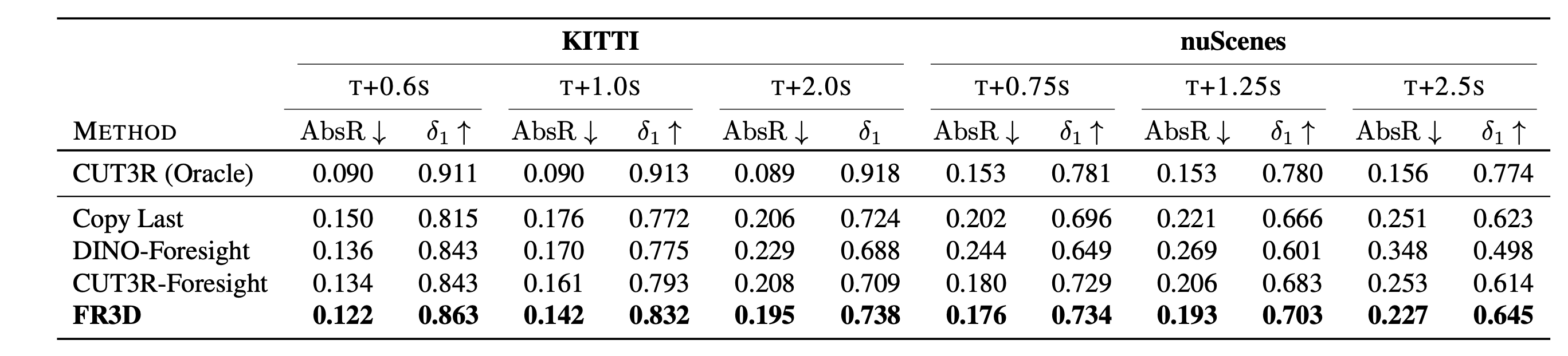
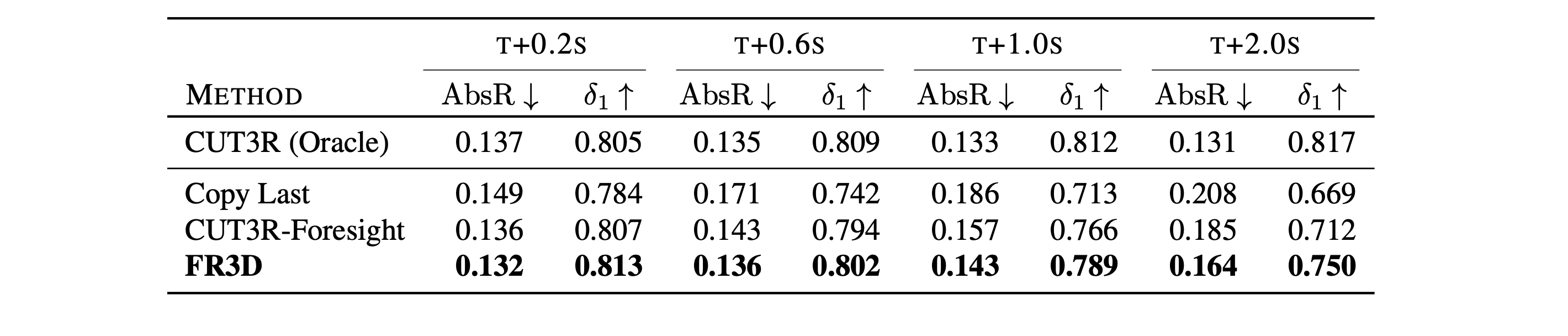
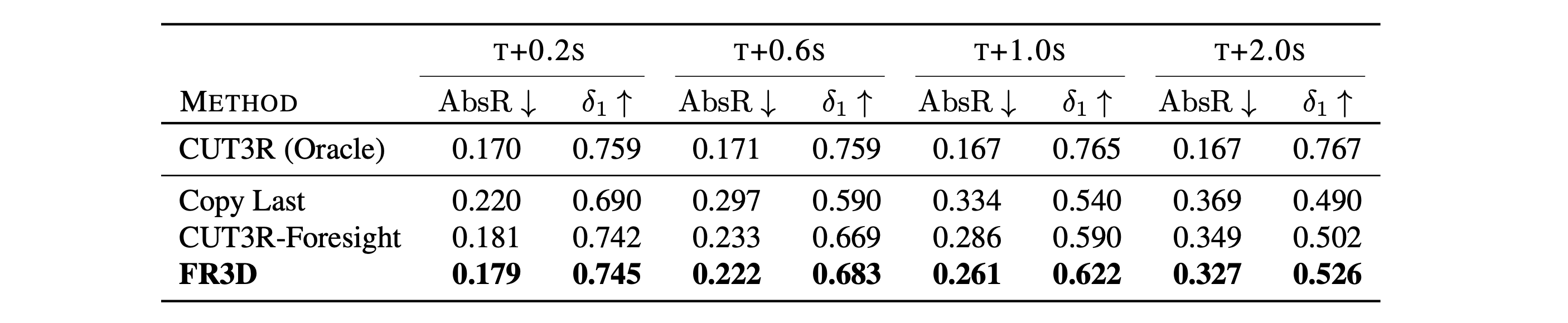
FR3D delivers strong results for depth and pose forecasting, also at long time horizons.
FR3D exhibits strong zero-shot results on KITTI and nuScenes for depth and pose forecasting.

We also evaluate FR3D's depth forecasting performance for static and dynamic regions against Copy Last and CUT3R-Foresight on the Waymo Open dataset. FR3D outperforms both of them being especially strong for static regions supporting our assumption that sharing information between pose and depth primarily benefits the depth prediction of static scene parts. Although FR3D outperforms the baselines in depth forecasting for dynamic regions, accurately modeling scene dynamics remains challenging.
@inproceedings{morbitzer_evers2026fr3d,
title = {Future Dynamic 3D Reconstruction: A 3D World Model with Disentangled Ego-Motion},
author = {Morbitzer, Nils and Evers, Jonathan and Savkin, Artem and Stauner, Thomas and Navab, Nassir and Tombari, Federico and Gasperini, Stefano},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
series = {Proceedings of Machine Learning Research},
publisher = {PMLR},
year = {2026},
}This site is hosted on GitHub Pages. GitHub may process technical data such as IP address, user agent, request logs, analytics, and security-related data. This site does not control GitHub's processing. GitHub privacy statement.
